
UniEmbed | Universal Embedding and Semantic Representation Toolkit v3.0
UniEmbed | Universal Embedding and Semantic Representation Toolkit v3.0
BUNDLE & SAVE
Couldn't load pickup availability
-
Ordered
-
Order Ready
-
Delivered
UniEmbed | Universal Embedding and Semantic Representation Toolkit v3.0
Product attributes
Canonical product name: UniEmbed
Module type: Universal embedding and semantic representation toolkit
Primary category: Embeddings
Secondary categories: Semantic search, retrieval preparation, rule understanding, case similarity, knowledge representation
Intended users: AI engineers, knowledge system developers, RAG developers, decision system developers, platform teams
Applicable lifecycle stage: Knowledge representation, semantic retrieval, rule analysis, case indexing, explanation support
Typical inputs: Text documents, rule descriptions, entity records, case notes, structured context fields, queries
Typical outputs: Embedding vectors, similarity scores, retrieval ready records, semantic metadata, case or entity representations
Supported delivery format: ZIP package delivered automatically by email after purchase
Expected package contents: Source files, embedding examples, configuration templates, documentation, tests, sample semantic workflows
Runtime environment: Python based semantic processing environment
Integration mode: Embedding pipeline, semantic search layer, RAG preparation stage, explanation support layer, case retrieval module
Recommended skill level: Intermediate to advanced
Commercial rights: Full commercial use is permitted
Modification rights: Modification, embedding workflow customization, internal adaptation, and proprietary integration are permitted
Open source policy: Public open sourcing is prohibited
Redistribution policy: Resale, redistribution, sublicensing, or repackaging as a standalone module is prohibited
Production readiness note: Requires embedding model selection, domain vocabulary review, vector storage integration, retrieval evaluation, and privacy review
Validation standard: The module is considered valid when sample text can be converted into embeddings and similarity outputs are generated according to documentation
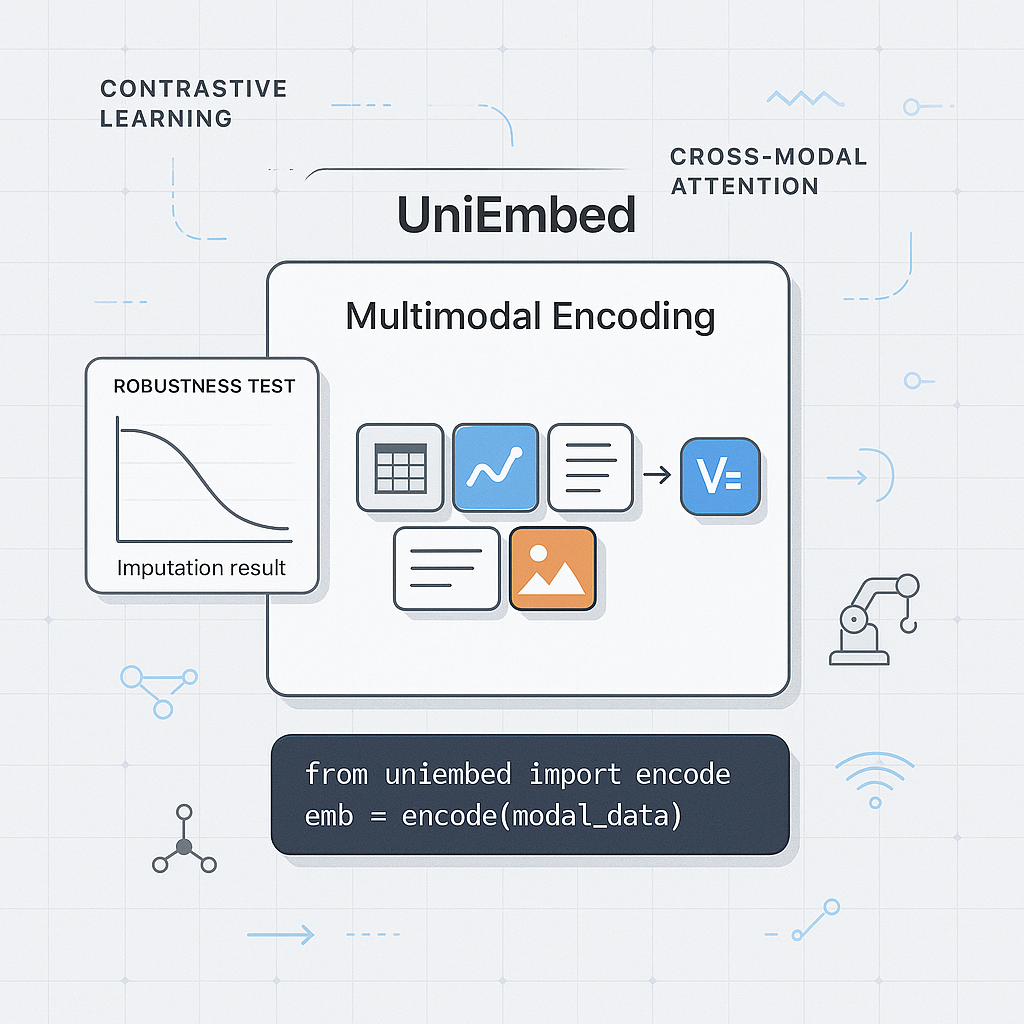
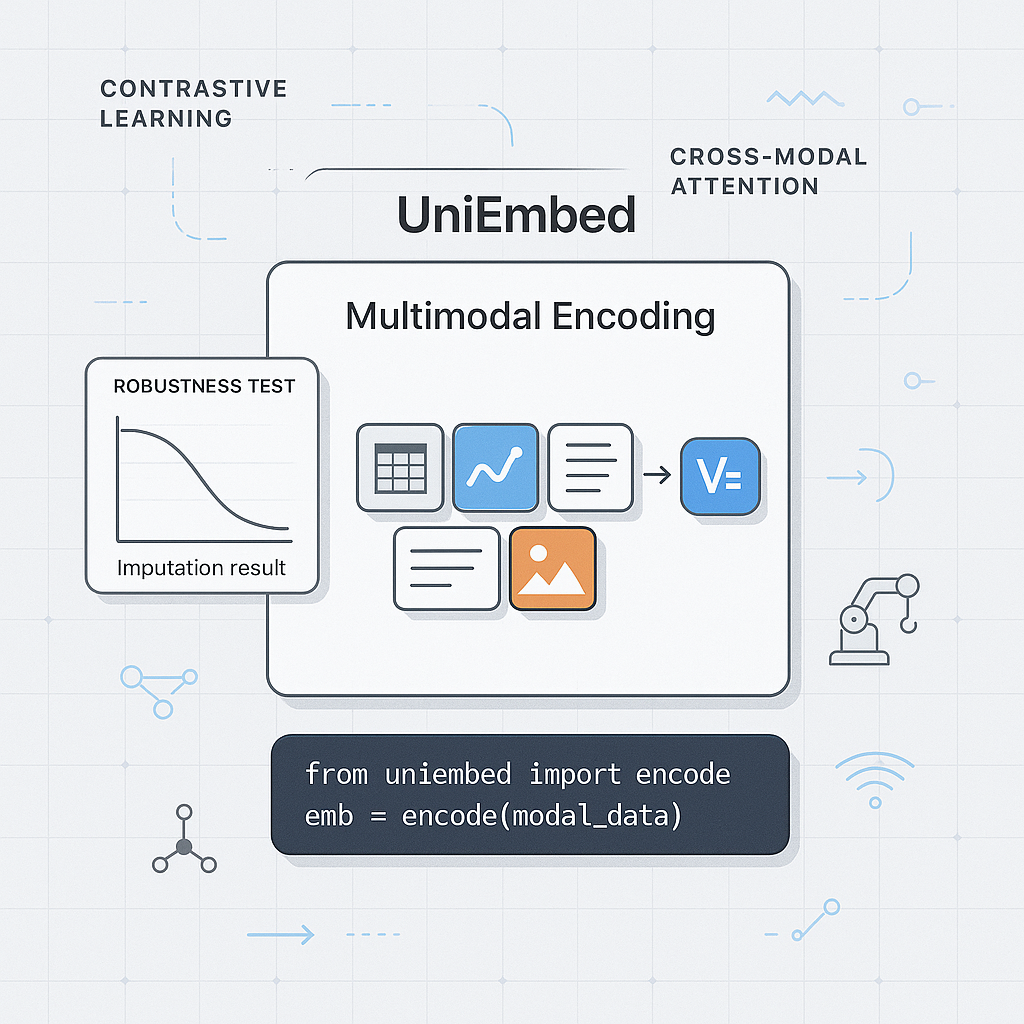
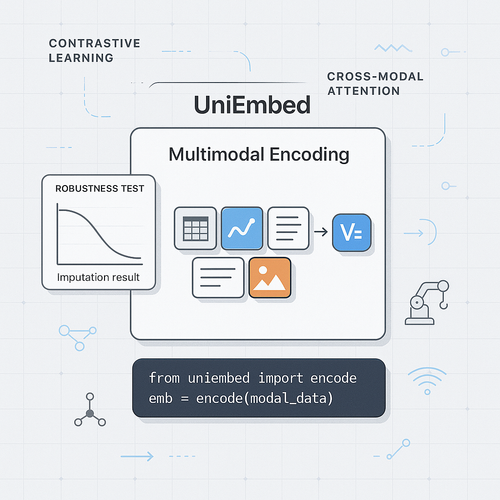
Description
UniEmbed is designed for teams that need to represent text, rules, documents, entities, or cases as vectors so that AI systems can search, compare, retrieve, and reason over them more effectively. Many AI workflows involve information that is not purely numeric. Rules, policy documents, customer cases, operational notes, strategy explanations, product descriptions, and technical documentation all contain useful knowledge. Without semantic representation, these materials remain difficult to connect to models or decision systems. UniEmbed provides workflows for generating embeddings, comparing semantic similarity, preparing retrieval inputs, and representing entities or cases in a reusable way. It can support RAG preparation, rule retrieval, case search, explanation systems, knowledge bases, and decision review workflows. For example, a decision engine may need to retrieve similar past cases or relevant rule descriptions to explain a recommendation. The module does not automatically build a complete RAG system. Users still need to choose embedding models, manage vector storage, design chunking strategies, evaluate retrieval quality, and handle privacy or access control. When used properly, UniEmbed becomes a semantic bridge between unstructured knowledge and structured AI workflows.